

【数分面试宝典】大厂高频SQL笔试题(三)
- 2026-07-13 15:22:56
【数分面试宝典】大厂高频SQL笔试题(三)01 写在前面 无论你是刚毕业的职场小鲜肉、还是想转行数据分析的小白玩家,只要想进入数据分析的行业,都逃不过数据分析面试的考验,这里最重要也是最关键的一关就是SQL笔试了,不过不用担心,结合作者6年+的工作和面试经验,系统全面地整理了数据分析面试中那些高频出现的以及各大厂的SQL笔试题,学习了这些笔试题的常见套路和解法,把这些题目都刷一遍,在接下来的笔试中应该可以一往无前,收割offer啦! 
02 计算留存率 03 计算分类TopN 04 计算连续得分 rank() over(order by score_time) as rn_all rank() over(partition by user_id order by score_time) as rn_user 以上就是数分面试宝典系列—SQL高频笔试题第3篇文章的内容,部分历史文章请回翻公众号,更多数据分析面试笔试的文章持续更新中,敬请期待,如果觉得不错,也欢迎分享、点赞和点在看哈~
数据分析笔试中最常见也是最有难度的就是SQL窗口函数了,SQL窗口函数作为SQL的高阶语法,也是数分工作中最常用的分析函数,也是面试中最常考查的知识点,本文就讲解了各大厂考查的窗口函数题目,通过这些题目就能熟练掌握这个知识点了。

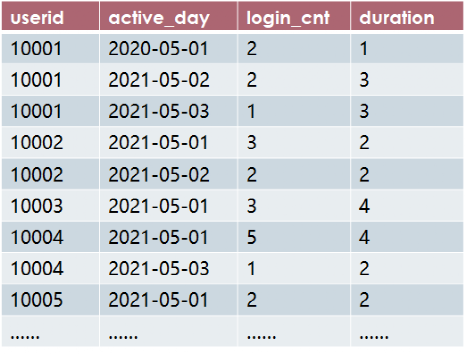
留存率是用户运营中非常关键的指标,也是面试中非常喜欢考查的题型,给出如下某个App的活跃日志表active_log,记录了某个用户userid每天active_day在App上登录次数login_cnt 和登录时长duration(分钟),如下图。
需求:计算该App的次日留存率和7日留存率。
第1步:自连接进行日期连接
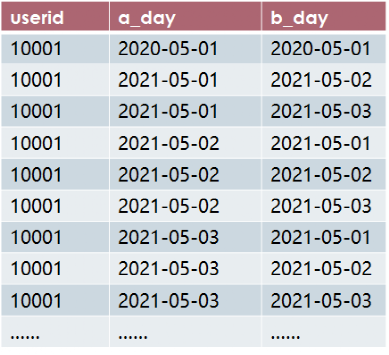
计算时间间隔类问题,我们需要使用自联结,得到如下形式的格式对于计算留存率十分关键,我们把临时表放到tmp_1表中。
create table tmp_1 asselect distinct a.userid,a.active_day as a_day,b.active_day as b_dayfrom active_log as aleft join active_log as bon a.userid=b.userid;
查询结果:
第2步:计算时间间隔
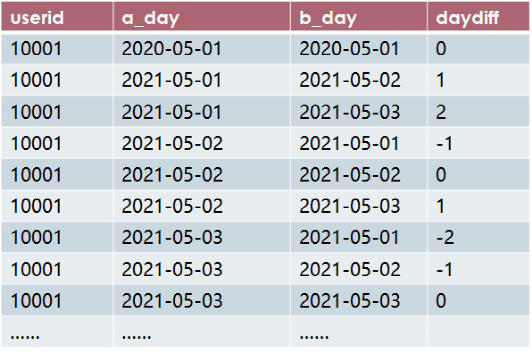
自连接后,计算时间间隔day_diff
select *,date_sub(b_day,a_day) as day_difffrom tmp_1;
查询结果:
第3步:计算次日、7日留存数
使用case when 计算次日留存数、7日留存数
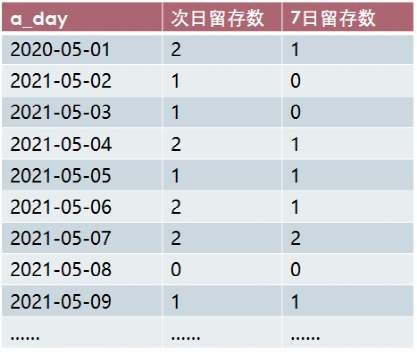
select d.a_day,count(distinct case when d.day_diff=1 then d.userid else null end) as '次日留存数' ,count(distinct case when d.day_diff=7 then d.userid else null end) as '7日留存数'from(select *,date_sub(b_day,a_day) as day_difffrom tmp_1) dgroup by d.a_day;
查询结果:
第4步:完整SQL代码
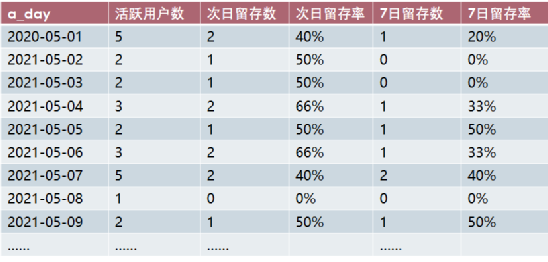
计算每日的活跃用户数,次日、7日留存率的完整的代码如下:
select d.a_day,count(distinct d.userid) as '活跃用户数',count(distinct case when d.day_diff=1 then d.userid else null end) as '次日留存数',count(distinct case when day_diff=1 then d.userid else null end)/count(distinct d.userid) as '次日留存率',count(distinct case when d.day_diff=3 then d.userid else null end)as '3日留存数',count(distinct case when day_diff=3 then d.userid else null end)/count(distinct d.userid) as '3日留存率',count(distinct case when d.day_diff=7 then d.userid else null end) as '7日留存数' ,count(distinct case when day_diff=7 then d.userid else null end)/count(distinct d.userid) as '7日留存率'from(select *,date_sub(b_day,a_day) as day_difffrom tmp_1) dgroup by d.a_day;
完整的结果如下:
另外一个非常常见的场景是计算前几名TopN,比如每个商品类别下最受欢迎的TopN产品,每个片区销售额最高的TopN店铺等。
假设有一个网店,上线了100多个商品,每个顾客浏览任何一个商品时都会产生一条浏览记录,浏览记录存储的表名为product_view,访客的用户id为user_id,浏览的商品名称是product_id。
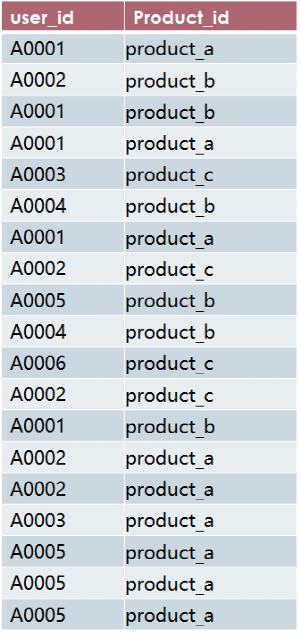
需求:每个商品浏览次数top3的用户信息,输出商品id、用户id、浏览次数。
第1步:计算每个商品被每个用户浏览的次数
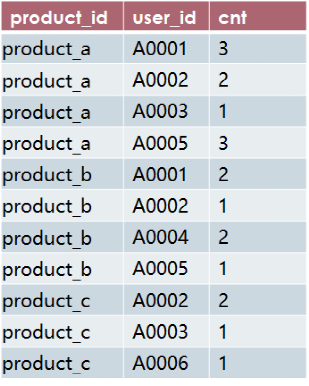
因为我们最终需要获取每个商品浏览量top3的用户信息,所以第一步,我们要先把每个商品下每个用户的浏览次数计算出来,放在临时表t1中。
create table t1 asselect product_id,user_id,count(*) cntfrom product_viewgroup by product_id,user_id;
查询结果:
第2步:每个商品被浏览次数排名
有了上一步每个商品下的各用户的浏览量,我们想获取Top3浏览量的用户信息,毫无疑问,我们需要使用到排序的开窗函数 ,但是排序窗口函数有:ROW_NUMBER,RANK或者DENSE_RANK,我们应该用哪个呢?三个函数的区别如下:
ROW_NUMBER从1开始,按照ORDER BY的顺序,值相等时排名不出现并列;
RANK与ROW_NUMBER类似,只是值相等时,排名会并列,并会在名次中跳过并列排名继续排名;
DENSE_RANK与ROW_NUMBER类似,只是值相等时,排名会并列,并会在名次中紧接着并列的排名继续排名。
ROW_NUMBER对于相同数据的排名不是一样的,如果我们取Top3,出现了相同访问次数的数据,那我们都需要保留下来,所以这里我们使用RANK函数。
create table t2 asselect product_id,user_id,cnt,rank() over(partition by product_id order by cnt) rnfrom t1;
查询结果:
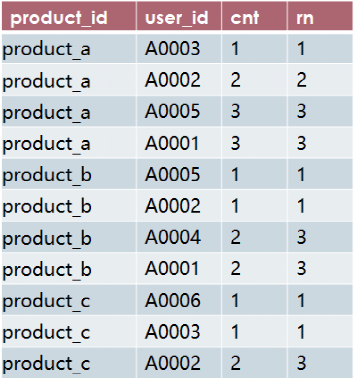
第3步:计算每个商品浏览前3的用户
有了第2步的结果,我们想要取每个商品浏览前三的用户信息就很简单了。
select product_id,user_id,cntfrom t2where rn<=3;
查询结果:
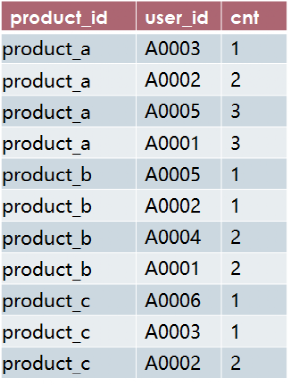
完整的SQL代码如下:
selectproduct_id,user_id,cntfrom(selectproduct_id,user_id,cnt,rank() over(partition by product_id order by cnt) rnfrom(selectproduct_id,user_id,count(*) cntfrom product_viewgroup byproduct_id,user_id)t1)t2where rn<=3;
现有一张表score_info记录了一场篮球比赛中各个球员的得分记录,即某个球员userid得分了,就记录该球员的得分时间score_time和得分score。如下表所示。
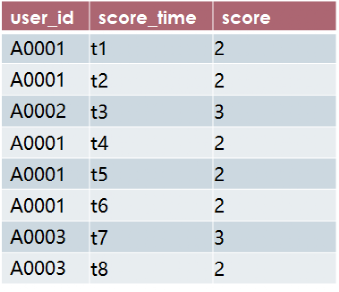
需求:计算连续3次得分的用户数,而且中间不能有别的球员得分。
因为要计算连续得分,这个时候我们的第一反应就应该是用窗口函数的排序RANK,但是需要计算每个球员连续3次得分,我们思考一下,如果一个球员连续三次得分,那么整体得分记录的次序和自己得分记录的次序是不是保持同步的增长,两者之间差一个恒定的值?如果这个恒定的值连续出现3次及以上,那么这个球员就应该是我们要统计的球员。
那么这个题目的核心问题就变成了计算:1、整体得分记录的次序;2、每个球员得分记录的次序。分别计算如下,分别用rn_all和rn_user表示。
得到的rn_all 和rn_user,以及diff = rn_all - rn_user如下所示:
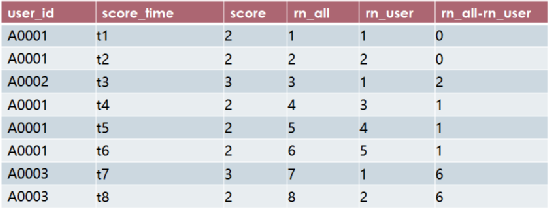
这时我们发现只需要对diff进行分组计数大于3个,就是连续点击大于三且中间没有其他人点击的用户。
完整的SQL代码如下:
select user_id,diff,count(1)from(select *, rn_all- rn_user as difffrom(select *,row_number() over( order by score_time) as rn_allrow_number() over( partition by user_id order by score_time) as rn_userfrom socre_info) a) bgroup by user_id,diffhaving count(1) >=3;
面试或者笔试的过程中会设定各种各样的场景,在这些场景下考查我们SQL的查询能力,但是万变不离其宗,业务场景只是一个表现形式,抽象为SQL问题后其实基本上就是我们这篇文章介绍的几类问题:计算累计、连续,分类TopN等。只要掌握这些问题的解法,并且可以举一反三,并不需要盲目的花费大量的时间精力去刷题,多总结多思考,你就很容易在面试笔试环节脱颖而出了。
END 加入数据万花筒的交流群,每日分享数据分析笔试面试题
Python 往期推荐!
数据思维|总结常用的数据分析思维和分析方法
数据分析师必会A/B 试验设计及其容易忽略的误区
Python实战|利用生存分析预测用户流失周期(一)
Python实战|利用生存分析预测用户流失周期(二)
数据分析如何学?最强攻略已经为你准备好了!
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

